
Making a Natural Language based LLM Recommendation System
Making a use case of Anime recommender system using llm and Langchain/LlamaIndex. Using graph database and normal Json query

GitHub
Overall Process for Development
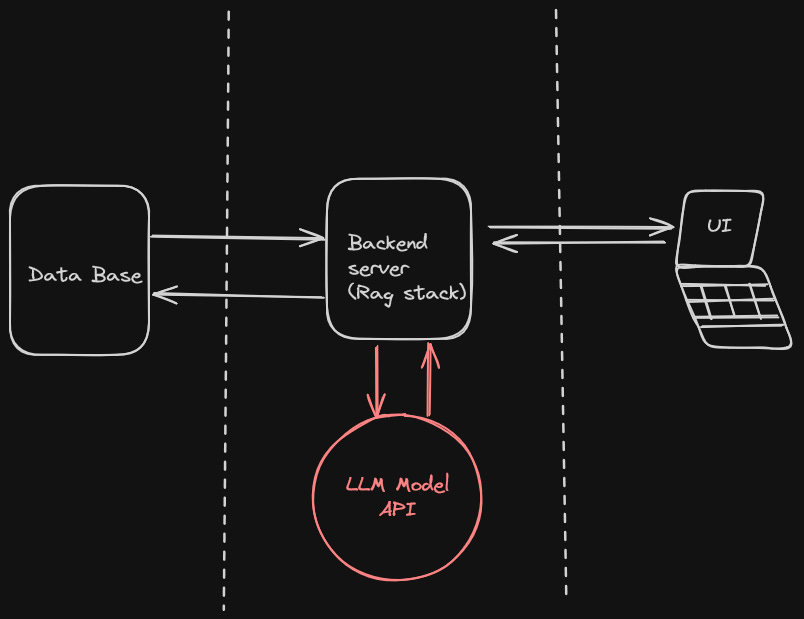
First step was to figure out what to do first so, I used 3 tier architecture to figure out how my recomender system will work.
So the plan is to work in following order:
Data scrapping
Database creation
Backend setup
Rag stack
model selection
performance comparison
User auth
UI (Still figuring out)
Data Scrapping
So to get data on anime, I used the following api Jikan API It has details regarding anime. Now we have to get the data of most anime that is available.
So let write a srcipt:
import requests
import re
import time
import tqdm
import json
base_url = "https://api.jikan.moe/v4/anime"
def replace_special_characters(input_string):
# Replace spaces and special characters with underscores
result = re.sub(r'[^a-zA-Z0-9]', '_', input_string)
return result
for i in tqdm.tqdm(range(1,26302)):
response = requests.request("GET", f"{base_url}/{i}/full", headers={}, data={})
if(response.status_code == 200):
res_json = response.json()
mal_id = res_json["data"]["mal_id"]
anime_name =replace_special_characters(res_json["data"]["titles"][0]["title"])
json.dump(res_json,open(f"data/json_data/{mal_id}_{anime_name}.json","w"))
time.sleep(1)
This will get us around ~26k anime data.
Database
Now that we have ourselves the data let’s start on making a database and a graph database.
First let’s Have a look at our data for a single anime.(I choose one of my fav😉).
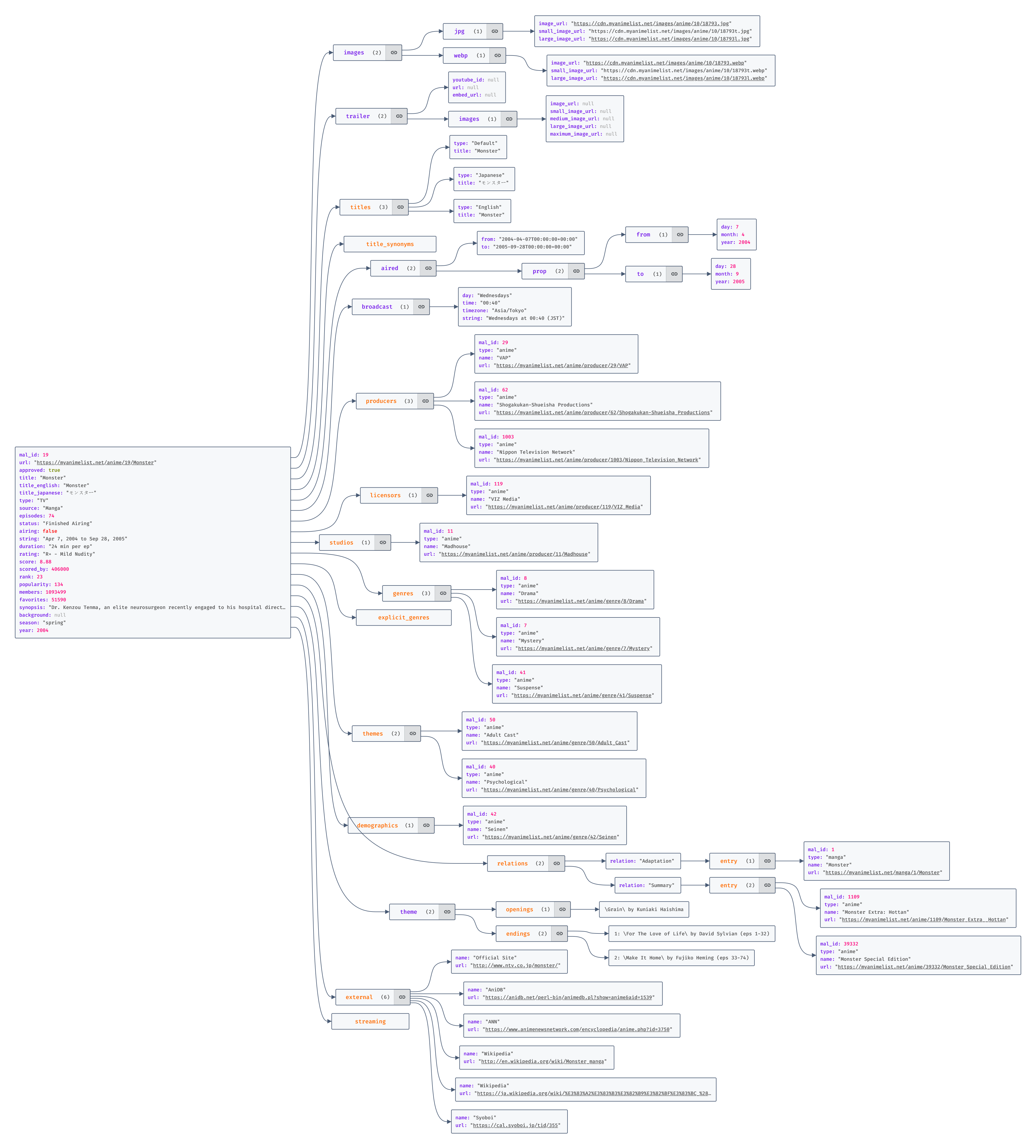
So for normal Json based index we are done.
But for Graph database creation i made following data model for neo4j based on above data:
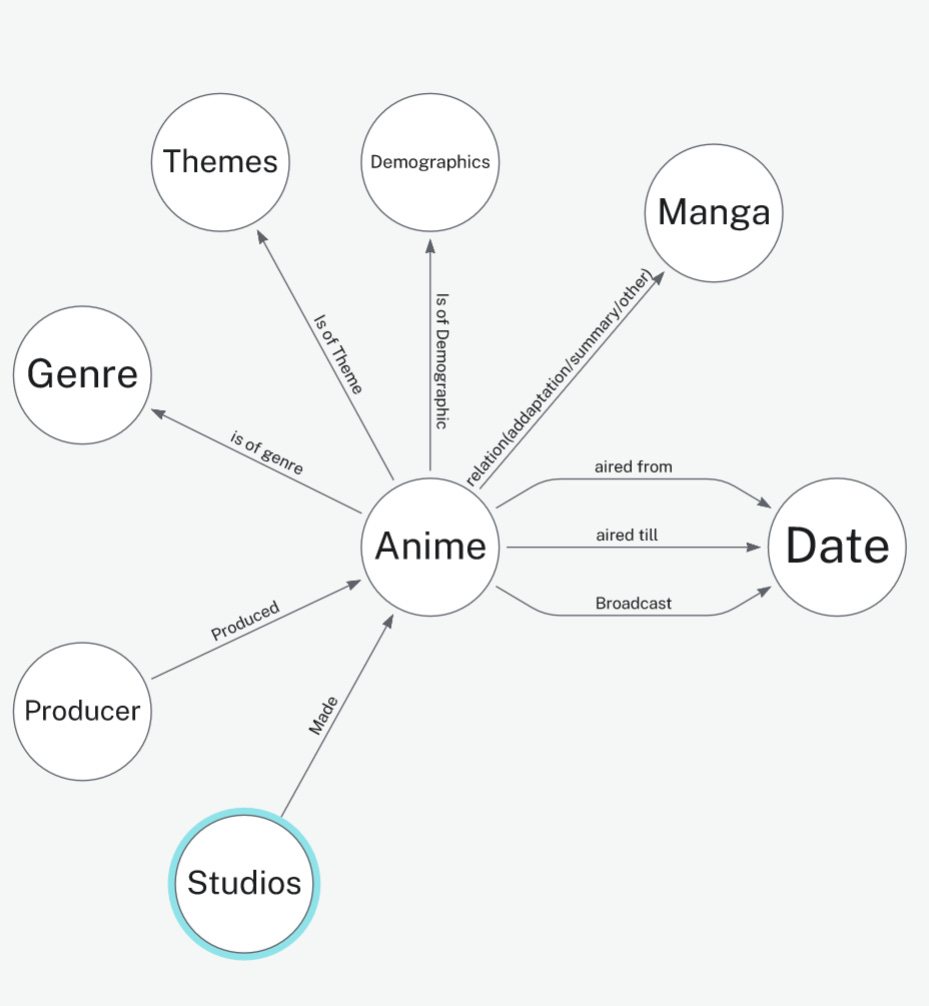
I’ll be using neomodel python package to create and interact with Graph database (Neo4j cloud database).
Here’s the data model:
from neomodel import (config, StructuredNode, StringProperty, IntegerProperty,
ArrayProperty ,UniqueIdProperty, RelationshipTo, FloatProperty, DateProperty)
from neomodel.contrib import SemiStructuredNode
class Date(StructuredNode):
Date = DateProperty()
class Synonyms(StructuredNode):#1
Synonyms_array = ArrayProperty(StringProperty())
class Genre(StructuredNode):#2
genre = StringProperty()
mal_id = IntegerProperty(unique_index=True)
class Producer(StructuredNode):#3
name = StringProperty()
url = StringProperty()
type = StringProperty()
mal_id = IntegerProperty(unique_index=True)
class Themes(StructuredNode):
name = StringProperty()
url = StringProperty()
type = StringProperty()
mal_id = IntegerProperty(unique_index=True)
class Demographics(StructuredNode):
name = StringProperty()
url = StringProperty()
type = StringProperty()
mal_id = IntegerProperty(unique_index=True)
class Manga(StructuredNode):
name = StringProperty()
url = StringProperty()
type = StringProperty()
mal_id = IntegerProperty(unique_index=True)
class Studios(StructuredNode):
name = StringProperty()
url = StringProperty()
type = StringProperty()
mal_id = IntegerProperty(unique_index=True)
#%%
class Anime(SemiStructuredNode):
mal_id = IntegerProperty(unique_index=True)#
url = StringProperty()#
title = StringProperty()#
type = StringProperty()#
source = StringProperty()#
episodes = IntegerProperty()#
status = StringProperty()#
airing = StringProperty()#
duration = StringProperty()#
rating = StringProperty()#
score = FloatProperty()#
scored_by = IntegerProperty()#
rank = IntegerProperty()#
popularity = IntegerProperty()#
members = IntegerProperty()#
favorites = IntegerProperty()#
synopsis = StringProperty()#
background = StringProperty()#
season = StringProperty()#
year = DateProperty()
# Relationships
aired_from = RelationshipTo(Date, 'aired_from')
aired_till = RelationshipTo(Date, 'aired_till')
broadcasted = RelationshipTo(Date, 'Broadcasted_on')
genres = RelationshipTo(Genre, 'is_of_genre')
producers = RelationshipTo(Producer, 'produced')
studios = RelationshipTo(Studios, 'made')
themes = RelationshipTo(Themes, 'is_of_theme')
demographics = RelationshipTo(Demographics, 'is_of_demographic')
manga = RelationshipTo(Manga, 'is adapted from')
synonyms= RelationshipTo(Synonyms,'is aslo called')
Graph DB visualization
Recommender System
Let’s first try out the json based inder and recomendation ai.
JSON Based Indexer
We have around 26k json data. And will use this as our knowledge base.
Let’s test out Json_querry_engine from llama Index
Graph Based Indexer
Will update
Comparisions
Will update